Matrizes como máquinas
Quando comecei a dialogar com o Claude a respeito da segunda parte dos diálogos sobre álgebra linear, me deparei com uma perspectiva interessante.
As matrizes eram logo apresentadas como um conjunto de vetores.
Mas não como entidades que atuam nos vetores.
Achei muito boa essa abordagem. Na primeira parte dos diálogos, discutimos muito sobre os vetores, então as matrizes agora, na segunda parte, chegam como máquinas.
Sem mais observações. Leia e acompanhe os diálogos. Busque responder. Participe da discussão.
Diálogo 1. Matrizes transformam vetores.
— O que seria uma matriz?
Uma matriz é uma tabela de números organizada em linhas e colunas.
Exemplo:
| 2 0 |
| 0 3 |
Isso é uma matriz 2×2 — duas linhas, duas colunas.
| 1 2 3 |
| 4 5 6 |
Isso é uma matriz 2×3 — duas linhas, três colunas.
Vetores também podem ser vistos como matrizes. [3, 5] é uma matriz 1×2, ou como coluna, uma matriz 2×1.
Por que organizar números assim? Porque essa estrutura permite definir operações úteis — principalmente multiplicar matriz por vetor.
— Entendi.
A ideia central desse módulo:
Matriz age sobre vetor → produz novo vetor.
É uma máquina. Entra vetor, sai vetor.
— Não entendi isso de agir sobre o vetor. Por que não o vetor que age sobre a matriz?
Pensa em função: f(x) = 2x.
Quem age sobre quem? A função f age sobre o número x. Você não diria que x age sobre f.
Matriz é a mesma ideia. A matriz é a função. O vetor é o input. A matriz define o que acontece. O vetor é o que sofre a transformação.
Por isso dizemos "aplicar a matriz ao vetor" — a matriz é o verbo, o vetor é o objeto.
— Muito interessante.
Então o que essa matriz faz com [1, 1]?
| 2 0 |
| 0 2 |
— Diria que resulta em [2, 2]?
Isso. E o que a matriz fez com o vetor?
Antes: [1, 1]. Depois: [2, 2].
— Mudou só o tamanho.
Exato. Mesma direção, dobrou o tamanho. Essa matriz é uma máquina de escalar.
Agora uma matriz diferente.
| 1 0 |
| 0 2 |
Aplica em [1, 1]. O que sai?
— Deixa o primeiro 1 o mesmo e dobra o segundo 1.
Isso. [1, 1] vira [1, 2]. A direção mudou?
— Penso que sim, porque era [1, 1] e ficou [1, 2]. Na segunda dimensão mudou, então mudou a direção do vetor.
Isso. [1, 1] aponta a 45 graus. [1, 2] aponta mais pra cima.
Essa matriz estica só na direção vertical. Então temos dois tipos de máquina.
| 2 0 |
| 0 2 |
Escala tudo igual. Direção preservada.
| 1 0 |
| 0 2 |
Escala diferente em cada eixo. Direção muda — exceto para vetores que já estão no eixo.
— Como assim "exceto para vetores que já estão no eixo"?
Pega a matriz:
| 1 0 |
| 0 2 |
Aplica em [1, 0] — um vetor no eixo x. Resultado: [1, 0]. Não mudou.
Aplica em [0, 1] — um vetor no eixo y. Resultado: [0, 2]. Dobrou, mas ainda aponta na mesma direção.
Aplica em [1, 1] — não está em nenhum eixo. Resultado: [1, 2]. Mudou de direção.
Vetores alinhados com os eixos não mudam de direção, só de tamanho. Vetores "no meio" mudam de direção.
Isso vai ser importante quando chegarmos em autovetores — são exatamente os vetores que não mudam de direção quando a matriz age.
Diálogo 2. O que matrizes distintas realizam.
— Você viu que essa matriz escala tudo por 2:
| 2 0 |
| 0 2 |
E essa escala diferente em cada eixo:
| 1 0 |
| 0 2 |
Agora uma nova:
| -1 0 |
| 0 1 |
Se eu aplicar em [1, 0], o que você acha que sai?
— O resultado seria [-1, 0].
Isso. E se aplicar em [3, 5]?
— Seria [-3, 5].
Isso. O x inverte, o y fica igual. Se você desenhar [3, 5] e [-3, 5] no plano, como descreveria a relação entre eles?
— Eles estão em lados opostos no eixo x, mas no mesmo ponto no eixo y.
Exato. É um espelho. Reflexão no eixo y. Agora uma matriz diferente:
| 0 -1 |
| 1 0 |
Aplica em [1, 0]. O que sai?
— O resultado seria [0, 0]?
Não. Vamos com calma. A regra: cada linha da matriz combina com o vetor.
Primeira linha [0, -1] com [1, 0]: 0×1 + (-1)×0 = ?
Segunda linha [1, 0] com [1, 0]: 1×1 + 0×0 = ?
Tenta de novo.
— Tá bom. O resultado seria [0, 1]?
Isso. [1, 0] virou [0, 1]. Antes apontava pra direita. Agora aponta pra cima. O que essa matriz fez geometricamente?
— Mudou a direção do vetor.
Sim, mas de que forma? [1, 0] aponta pra direita. [0, 1] aponta pra cima. Quantos graus girou? Em que sentido?
— Mudou 90 graus para cima.
Isso. Rotação de 90 graus no sentido anti-horário. Vamos confirmar. Aplica a mesma matriz em [0, 1]. O que sai?
— Desculpe, [-1, 0]. Então, foi de 90 graus no sentido anti-horário.
Isso. [0, 1] virou [-1, 0]. Apontava pra cima, agora aponta pra esquerda. 90 graus anti-horário de novo. Essa matriz sempre rotaciona 90 graus anti-horário, qualquer que seja o vetor.
Agora mais uma transformação:
| 1 1 |
| 0 1 |
Aplica em [1, 0]. O que sai?
— O resultado seria [1, 0].
Isso. Não mudou nada. Agora aplica em [0, 1]. O que sai?
— O resultado seria [1, 1].
Isso. [0, 1] virou [1, 1]. O vetor que apontava pra cima agora aponta na diagonal.
Então: [1, 0] ficou [1, 0] — não mudou. E [0, 1] virou [1, 1] — inclinou pra direita.
Isso se chama cisalhamento (shear). Imagina um retângulo virando um paralelogramo — um lado fica fixo, o outro inclina.
— Ficou difícil de compreender. Poderia gerar um resumo final com os gráficos?
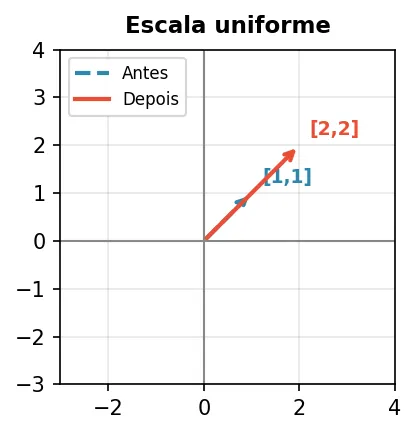
Claro. Aqui estão as cinco transformações básicas:
Escala uniforme — dobra o tamanho, mesma direção.
| 2 0 |
| 0 2 |
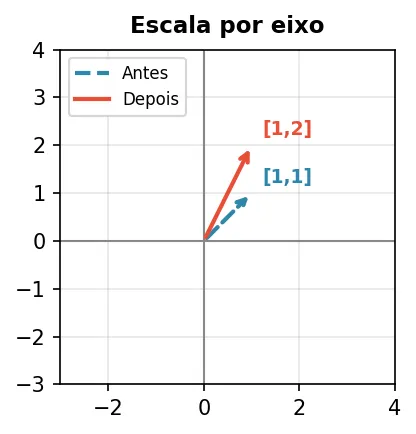
Escala por eixo — só o y dobra, direção muda.
| 1 0 |
| 0 2 |
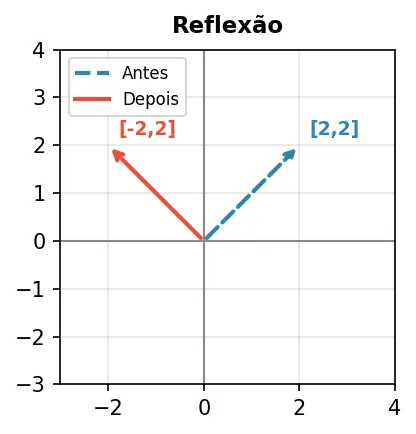
Reflexão — espelha no eixo y.
| -1 0 |
| 0 1 |
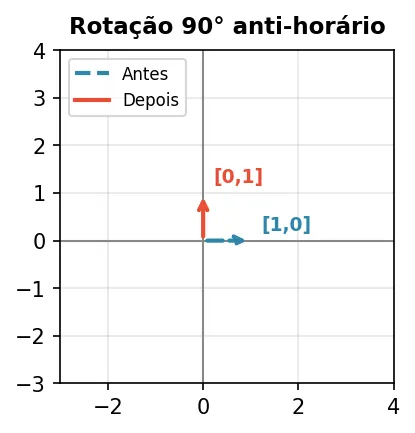
Rotação 90° anti-horário — gira 90°.
| 0 -1 |
| 1 0 |
Cisalhamento — o vetor vertical inclina, o horizontal fica igual.
| 1 1 |
| 0 1 |
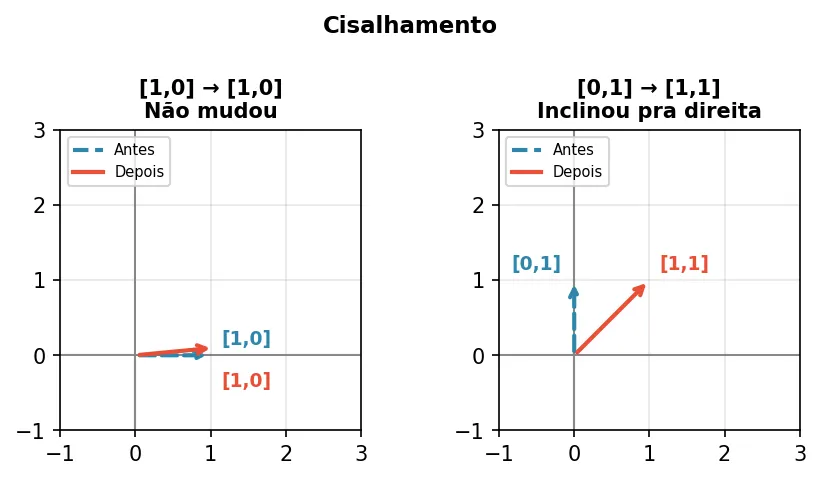
Toda transformação linear em 2D é alguma combinação dessas.
Diálogo 3. Multiplicação matriz-vetor.
— Você já viu os resultados de aplicar matrizes a vetores. Agora vamos entender a mecânica.
| a b | | x |
| c d | × | y |
A regra: cada linha da matriz realiza um produto interno com o vetor.
Primeira linha [a, b] com [x, y] → a×x + b×y → primeiro componente. Segunda linha [c, d] com [x, y] → c×x + d×y → segundo componente.
Resultado:
| a×x + b×y |
| c×x + d×y |
Tenta aplicar:
| 3 1 | | 2 |
| 0 2 | × | 1 |
O que dá?
— Seria [7, 2]?
Isso.
Primeira linha: 3×2 + 1×1 = 7 Segunda linha: 0×2 + 2×1 = 2
Agora uma pergunta conceitual. Olha essa multiplicação de outro ângulo:
| 3 1 | | 2 |
| 0 2 | × | 1 |
A matriz tem duas colunas: [3, 0] e [1, 2].
E se eu te dissesse que o resultado também pode ser calculado assim:
2 × [3, 0] + 1 × [1, 2] = ?
Tenta.
— Assim não deu para compreender. Como procederia?
Vou devagar.
A matriz tem duas colunas:
| 3 1 |
| 0 2 |
Primeira coluna: [3, 0] Segunda coluna: [1, 2]
O vetor é [2, 1].
O primeiro número do vetor (2) multiplica a primeira coluna. O segundo número do vetor (1) multiplica a segunda coluna. Depois soma.
2 × [3, 0] = [6, 0] 1 × [1, 2] = [1, 2]
Soma: [6, 0] + [1, 2] = ?
— O resultado seria [7, 2] mesmo.
Exato. Mesmo resultado, duas formas de ver:
- Por linhas: cada linha realiza produto interno com o vetor.
- Por colunas: o vetor diz como combinar as colunas da matriz.
A visão por colunas é poderosa. Significa que multiplicar matriz por vetor é uma combinação linear das colunas.
O vetor [2, 1] diz: "pegue 2 da primeira coluna e 1 da segunda."
Isso vai ser importante quando falarmos dos quatro subespaços fundamentais.
Mais uma prática. Calcula:
| 1 0 2 | | 3 |
| 4 1 0 | × | 1 |
| 2 |
Usa o método que preferir.
— O resultado seria [7, 13].
Isso.
Primeira linha: 1×3 + 0×1 + 2×2 = 7 Segunda linha: 4×3 + 1×1 + 0×2 = 13
Nota que a matriz era 2×3 e o vetor tinha 3 componentes. O resultado tem 2 componentes.
Regra geral: matriz m×n vezes vetor de n componentes = vetor de m componentes.
O número de colunas da matriz precisa ser igual ao tamanho do vetor. Senão não funciona.
O que acontece se eu tentar multiplicar uma matriz 2×3 por um vetor de 2 componentes?
— Pela regra não funciona.
Isso. As dimensões não batem. A matriz espera 3 números, você deu 2.
Diálogo 4. Multiplicação matriz-matriz.
— Você viu que uma matriz transforma um vetor. E se você aplicar duas matrizes em sequência?
Primeiro aplica A, depois aplica B.
Exemplo:
A = | 1 1 | B = | 2 0 |
| 0 1 | | 0 2 |
Pega o vetor [1, 0].
Primeiro aplica A em [1, 0]. O que dá?
— Daria [1, 0].
Isso. A matriz A não mudou [1, 0] — é o cisalhamento que vimos antes.
Agora aplica B em [1, 0]. O que dá?
— Daria [2, 0].
Isso. A matriz B dobra tudo.
Agora vamos juntar. Aplica A em [1, 0], depois aplica B no resultado.
A × [1, 0] = [1, 0]. B × [1, 0] = [2, 0].
Resultado final: [2, 0].
Pergunta: será que existe uma única matriz C que transforma [1, 0] direto em [2, 0], igual a aplicar A e depois B?
— Talvez uma matriz parecida com a A, mas que usa 2 como a B.
Boa intuição. Vamos descobrir qual é essa matriz.
A ideia: multiplicar duas matrizes significa combinar suas transformações em uma só.
Para calcular C = B × A, pensamos assim: cada coluna de C é o resultado de B aplicado à coluna correspondente de A.
A tem duas colunas: [1, 0] e [1, 1].
Aplica B em [1, 0]. O que dá?
— Daria [2, 0].
Isso. Essa é a primeira coluna de C.
Agora aplica B em [1, 1] — a segunda coluna de A. O que dá?
— Daria [2, 2].
Isso. Essa é a segunda coluna de C.
Então:
C = | 2 2 |
| 0 2 |
Vamos verificar. Aplica C direto em [1, 0]. O que dá?
— Daria [2, 0].
Isso. Mesmo resultado que aplicar A e depois B.
Multiplicar matrizes = compor transformações.
B × A significa: primeiro aplica A, depois aplica B.
Parece invertido, mas pensa assim: B × A × v = B × (A × v). O vetor v encontra A primeiro.
Agora uma pergunta importante. Será que A × B dá o mesmo que B × A?
Vamos testar. Calcula A × B.
A primeira coluna de B é [2, 0]. Aplica A em [2, 0]. O que dá?
— Daria [2, 0].
Isso. Agora aplica A em [0, 2] — a segunda coluna de B. O que dá?
— Daria [2, 2].
Isso. Então:
A × B = | 2 2 |
| 0 2 |
Espera. Isso é igual a B × A.
Nesse caso específico, deu igual. Mas isso aconteceu porque B é uma matriz especial — ela escala tudo por 2. É como multiplicar por um número.
Vamos testar com outras matrizes onde a ordem importa.
A = | 1 1 | B = | 0 -1 |
| 0 1 | | 1 0 |
A é cisalhamento. B é rotação 90°.
Calcula B × A. Aplica B na primeira coluna de A, que é [1, 0]. O que dá?
— Daria [0, 1].
Isso. Agora aplica B na segunda coluna de A, que é [1, 1]. O que dá?
— Daria [-1, 1].
Isso. Então:
B × A = | 0 -1 |
| 1 1 |
Agora calcula A × B. Aplica A na primeira coluna de B, que é [0, 1]. O que dá?
— Daria [1, 1].
Isso. Agora aplica A na segunda coluna de B, que é [-1, 0]. O que dá?
— Daria [-1, 0].
Isso. Então:
A × B = | 1 -1 |
| 1 0 |
Agora compara:
B × A = | 0 -1 |
| 1 1 |
A × B = | 1 -1 |
| 1 0 |
São iguais?
— Os resultados não são iguais.
Exato. A ordem importa.
Cisalhar e depois rotacionar não é o mesmo que rotacionar e depois cisalhar.
Isso se chama: multiplicação de matrizes não é comutativa.
A × B ≠ B × A (em geral).
É diferente de números, onde 3 × 5 = 5 × 3.
Diálogo 5. Os quatro subespaços fundamentais.
— Toda matriz carrega quatro subespaços. Vamos descobrir quais são.
Pega essa matriz:
A = | 1 2 |
| 2 4 |
Lembra que multiplicar matriz por vetor é combinação linear das colunas?
As colunas de A são [1, 2] e [2, 4].
Qual é o span dessas colunas?
— Elas são linearmente dependentes, então, apesar de terem dimensão 2, não geram o plano. O span seria uma linha?
Exato. [2, 4] = 2 × [1, 2]. Redundante.
O span das colunas é uma linha — todos os múltiplos de [1, 2].
Esse span tem nome: espaço coluna de A.
É o conjunto de todos os vetores que A consegue produzir. Se você pegar qualquer vetor v e calcular A × v, o resultado sempre cai no espaço coluna.
Agora outra pergunta. Existe algum vetor v ≠ [0, 0] tal que A × v = [0, 0]?
— Acho que não. Para dar zero em cada posição do vetor, teria que multiplicar por 0.
Vamos testar. Tenta esse vetor: v = [-2, 1].
Calcula A × v.
— O resultado seria [0, 0].
Isso. A matriz "matou" esse vetor.
O conjunto de todos os vetores que A transforma em [0, 0] tem nome: espaço nulo de A.
Nesse caso, o espaço nulo é todos os múltiplos de [-2, 1]. Uma linha.
Nota algo interessante: o espaço coluna é uma linha, o espaço nulo é outra linha. Juntos, dimensão 1 + 1 = 2, que é o número de colunas.
Isso não é coincidência. É um teorema.
Agora as linhas. A matriz A tem linhas [1, 2] e [2, 4].
Qual é o span das linhas?
— Mesmo span, uma linha de todos os múltiplos de [1, 2].
Isso. Esse é o espaço linha de A.
Agora o quarto. Existe algum vetor w tal que w × A = [0, 0]?
Aqui o vetor vem da esquerda, não da direita.
Pensa: w = [w₁, w₂] multiplicando A.
[w₁, w₂] × | 1 2 | = [w₁×1 + w₂×2, w₁×2 + w₂×4]
| 2 4 |
Para dar [0, 0], precisa:
w₁ + 2w₂ = 0 2w₁ + 4w₂ = 0
Consegue achar um w?
— Poderia ser w = [-2, 1].
Isso. Vamos verificar.
[-2, 1] × | 1 2 | = [(-2)×1 + 1×2, (-2)×2 + 1×4] = [0, 0]
| 2 4 |
Funciona. Esse é o espaço nulo à esquerda de A.
Nota que nessa matriz, o espaço nulo e o espaço nulo à esquerda são iguais. Isso aconteceu porque A é simétrica — as linhas e colunas são as mesmas.
— Esses subespaços têm alguma relação geométrica? Olha os vetores [1, 2] e [-2, 1].
Calcula o produto interno entre [1, 2] e [-2, 1].
[1, 2] · [-2, 1] = 1×(-2) + 2×1 = ?
— O resultado seria 0.
Isso. Produto interno zero. São perpendiculares.
O espaço coluna e o espaço nulo à esquerda são ortogonais. O espaço linha e o espaço nulo são ortogonais.
Isso sempre acontece, pra qualquer matriz. Os quatro subespaços se organizam em dois pares perpendiculares.
— Tem como visualizar isso?
Sim. Para essa matriz específica.
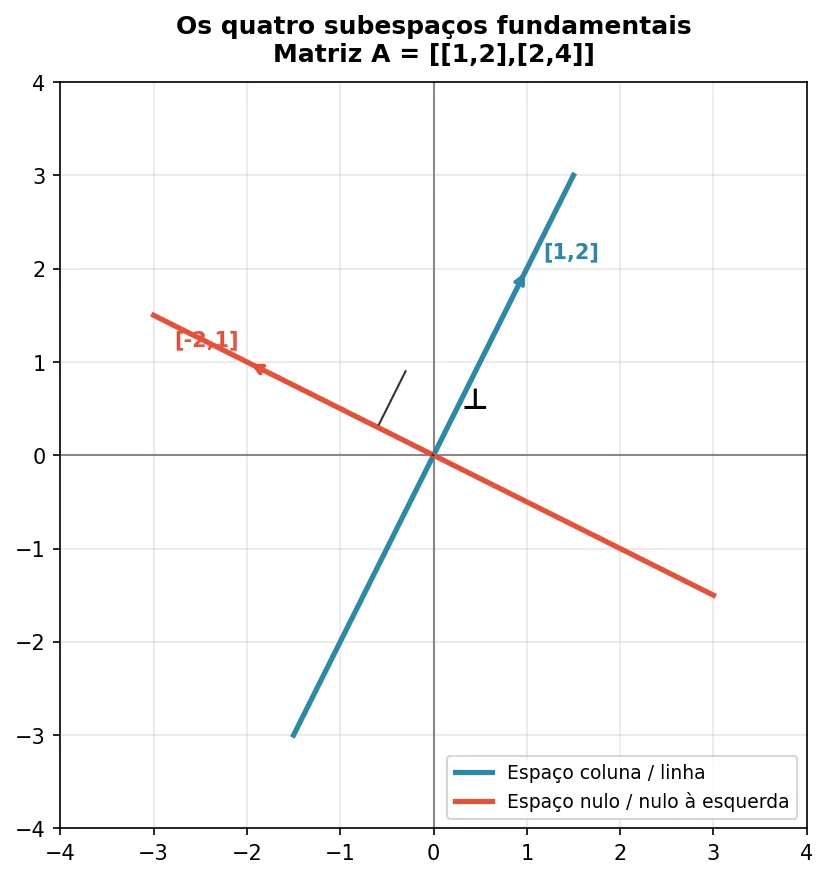
Na imagem aparecem duas linhas, não quatro. Por quê?
Porque essa matriz é simétrica — as linhas são iguais às colunas. Então:
- Espaço coluna = espaço linha (linha azul, múltiplos de [1, 2])
- Espaço nulo = espaço nulo à esquerda (linha vermelha, múltiplos de [-2, 1])
Em matrizes não simétricas, os quatro subespaços seriam distintos. Mas sempre em pares perpendiculares.
O símbolo ⊥ indica a perpendicularidade: as duas linhas se cruzam em ângulo reto.
Resumo.
- Espaço coluna. O que a matriz consegue produzir.
- Espaço nulo. O que a matriz mata.
- Espaço linha. Span das linhas.
- Espaço nulo à esquerda. O que mata a matriz pela esquerda.
- Coluna ⊥ Nulo à esquerda.
- Linha ⊥ Nulo.
Diálogo 6. Rank — a dimensionalidade verdadeira.
— Você viu que a matriz:
A = | 1 2 |
| 2 4 |
Tem espaço coluna de dimensão 1 — uma linha.
Essa dimensão do espaço coluna tem nome: rank (ou posto).
O rank de A é 1.
Agora outra matriz:
B = | 1 0 |
| 0 1 |
Quais são as colunas? São linearmente independentes ou dependentes?
— As colunas são [1, 0] e [0, 1]. Elas são linearmente independentes.
Isso. E qual é o span dessas colunas?
— O span seria o plano.
Isso. O plano inteiro. Dimensão 2.
Então o rank de B é 2.
Compara:
| Matriz | Rank | Espaço coluna |
|---|---|---|
| A | 1 | Linha |
| B | 2 | Plano |
O rank diz quantas dimensões a matriz "consegue alcançar" na saída.
Agora uma pergunta. A matriz A é 2×2. O rank é 1. A matriz B é 2×2. O rank é 2.
Qual é o rank máximo possível para uma matriz 2×2?
— O rank máximo para uma matriz 2×2 seria 2.
Isso. Não pode ter mais colunas independentes do que colunas existem.
E para uma matriz 3×2? Qual o rank máximo?
— Para matriz 3×2, o rank máximo seria 2.
Isso. Só tem 2 colunas, então no máximo 2 independentes.
E para uma matriz 2×3? Qual o rank máximo?
— O rank máximo seria 3.
Não. Pensa assim.
Uma matriz 2×3 tem 3 colunas. Mas cada coluna é um vetor de dimensão 2 — vive no plano.
No plano, qual o número máximo de vetores independentes?
— Sim, desculpe, entendi. No plano, o número máximo de vetores independentes seria 2.
Isso. Então o rank máximo de uma matriz 2×3 é 2.
Regra geral: rank ≤ min(linhas, colunas).
Agora lembra do diálogo anterior. O espaço coluna tinha dimensão 1, o espaço nulo tinha dimensão 1. Juntos: 1 + 1 = 2 = número de colunas.
Isso é um teorema importante:
rank + dimensão do espaço nulo = número de colunas
Se a matriz é 2×3 e o rank é 2, qual a dimensão do espaço nulo?
— A dimensão do espaço nulo seria 1.
Isso. 2 + 1 = 3.
Intuitivamente: se a matriz "usa" 2 dimensões pra produzir saída, sobra 1 dimensão que ela "mata" — o espaço nulo.
— Espera. Poderia mostrar essa dimensão que ela mata?
Claro. Olha a matriz A:
![]()
Lado esquerdo — Entrada:
- Todos os vetores do plano podem entrar na matriz
- A linha vermelha é o espaço nulo — vetores como [-2, 1] e seus múltiplos
- As setas azuis são outros vetores quaisquer
Lado direito — Saída:
- A matriz A transforma tudo
- Os vetores do espaço nulo (linha vermelha) viram o ponto [0, 0] — foram "matados"
- Todos os outros vetores caem na linha azul (espaço coluna)
A matriz tem rank 1, então a saída é uma linha — perdeu uma dimensão. A dimensão perdida é exatamente o espaço nulo.
Rank 1 = produz 1 dimensão. Espaço nulo dimensão 1 = mata 1 dimensão. Total: 1 + 1 = 2 colunas.
— Entendi. Última pergunta. Se uma matriz 3×3 tem rank 3, qual a dimensão do espaço nulo?
— Se seria uma matriz 3×3 com rank 3, pelo teorema, a dimensão do espaço nulo seria 0.
Isso. 3 + 0 = 3.
A matriz não mata nada — só o vetor zero vai pro zero. Isso significa que a matriz é invertível. Vamos falar disso mais adiante.
— Por que rank alto mata pouco e rank baixo mata muito?
Volta pro teorema:
rank + dimensão do espaço nulo = número de colunas
Pega uma matriz 3×3 (3 colunas):
| Rank | Espaço nulo | O que mata |
|---|---|---|
| 3 | dimensão 0 | Só o [0,0,0] |
| 2 | dimensão 1 | Uma linha inteira |
| 1 | dimensão 2 | Um plano inteiro |
| 0 | dimensão 3 | Tudo |
Rank 3 → espaço nulo é só a origem → mata quase nada. Rank 1 → espaço nulo é um plano → mata uma infinidade de vetores.
"Matar" = transformar em [0, 0, 0].
Diálogo 7. Sistemas de equações lineares.
— Você já sabe que multiplicar matriz por vetor dá outro vetor:
A × x = b
Agora a pergunta inversa: dado A e b, como achar x?
Exemplo:
| 1 2 | | x | | 5 |
| 3 4 | × | y | = | 11|
Isso é o mesmo que resolver:
1x + 2y = 5. 3x + 4y = 11.
Consegue achar x e y?
— Consegui achar. Seria x = 1 e y = 2.
Isso. Vamos verificar:
1×1 + 2×2 = 1 + 4 = 5 ✓ 3×1 + 4×2 = 3 + 8 = 11 ✓
Agora pensa na visão por colunas. Lembra que A × x é combinação linear das colunas de A?
As colunas são [1, 3] e [2, 4].
O sistema pede: qual combinação de [1, 3] e [2, 4] dá [5, 11]?
Resposta: 1 × [1, 3] + 2 × [2, 4] = [5, 11].
Então resolver A × x = b é perguntar: b está no espaço coluna de A?
Se sim, existe solução. Se não, não existe.
Agora outro sistema:
| 1 2 | | x | | 1 |
| 2 4 | × | y | = | 3 |
Consegue achar x e y?
— O sistema seria 1x + 2y = 1 e 2x + 4y = 3. Consegui achar! Seria x = -2 e y = 1.
Vamos verificar.
1×(-2) + 2×1 = -2 + 2 = 0 ≠ 1.
Não bateu. Tenta de novo, ou pensa: essa matriz tem algo especial que já vimos antes?
— Desculpe, considerei buscando anular, mas teria que dar 1 na primeira equação. Sim, a matriz tem colunas linearmente dependentes e linhas linearmente dependentes.
Isso. Colunas dependentes — [2, 4] = 2 × [1, 2]. O espaço coluna é só uma linha: múltiplos de [1, 2].
O vetor [1, 3] está nessa linha? Seria [1, 3] = c × [1, 2] para algum c?
— O vetor [1, 3] não está nessa linha. Para nenhum c.
Isso. Se [1, 3] = c × [1, 2], então c = 1 pela primeira componente. Mas 1 × 2 = 2 ≠ 3.
O vetor [1, 3] não está no espaço coluna. Logo, o sistema não tem solução.
Agora outro:
| 1 2 | | x | | 2 |
| 2 4 | × | y | = | 4 |
O vetor [2, 4] está no espaço coluna de A?
— Sim, considerando que o espaço coluna seria [1, 2] e que [2, 4] está no espaço coluna. Para x = 0 e y = 1.
Isso. Verifica.
1×0 + 2×1 = 2 ✓. 2×0 + 4×1 = 4 ✓.
Mas essa matriz tem espaço nulo não trivial. Lembra qual vetor ela mata?
— Lembro. Acho que seria o vetor [-2, 1].
Isso. Então se [0, 1] é solução, o que acontece se somar [-2, 1]?
Tenta x = 0 + (-2) = -2 e y = 1 + 1 = 2.
Verifica se [-2, 2] também é solução.
— Daria 2 e 4. Seria solução.
Isso. Duas soluções. [0, 1] e [-2, 2].
Na verdade, infinitas soluções. Qualquer vetor da forma [0, 1] + t × [-2, 1] seria solução, para qualquer t.
t = 0 → [0, 1]. t = 1 → [-2, 2]. t = 2 → [-4, 3].
Por quê? Porque [-2, 1] está no espaço nulo — a matriz mata ele. Somar algo que vira zero não muda o resultado.
Resumo dos três casos.
| Sistema | Condição | Soluções |
|---|---|---|
| b fora do espaço coluna | — | Nenhuma |
| b no espaço coluna, espaço nulo = {0} | — | Única |
| b no espaço coluna, espaço nulo ≠ {0} | — | Infinitas |
O espaço coluna determina se há solução. O espaço nulo determina se é única.
Diálogo 8. Eliminação gaussiana e forma escalonada.
— Você resolveu sistemas por intuição. Agora um método sistemático.
A ideia: transformar o sistema em algo mais fácil de resolver, sem mudar as soluções.
Começa com:
| 1 2 | 5 |
| 3 4 | 11 |
Isso é a matriz aumentada — a matriz A com o vetor b colado do lado.
Operações permitidas:
- Trocar duas linhas
- Multiplicar uma linha por um número não zero
- Somar um múltiplo de uma linha a outra
Essas operações não mudam as soluções.
Objetivo: zerar abaixo da diagonal.
A primeira linha é [1, 2 | 5]. O elemento 1 é o pivô.
Para zerar o 3 na segunda linha, o que você faria?
— Para zerar o 3 na segunda linha, teria que multiplicar a primeira linha por -3.
Isso, e depois?
— Depois somar.
Isso. Linha 2 + (-3) × Linha 1.
Calcula: [3, 4 | 11] + (-3) × [1, 2 | 5] = ?
— O resultado seria [0, -2 | -4].
Isso. Agora a matriz aumentada ficou:
| 1 2 | 5 |
| 0 -2 | -4 |
Isso é a forma escalonada (row echelon form). Zeros abaixo da diagonal.
Agora resolve de baixo pra cima.
A segunda linha diz: -2y = -4. Quanto é y?
— O y seria 2.
Isso. Agora substitui na primeira linha.
A primeira linha diz: x + 2y = 5.
Com y = 2, quanto é x?
— O x seria 1.
Isso. x = 1, y = 2. Mesma solução que antes, agora com método sistemático.
Esse processo de resolver de baixo pra cima se chama substituição reversa (back substitution).
Agora vamos tentar com a matriz problemática:
| 1 2 | 1 |
| 2 4 | 3 |
Para zerar o 2 na segunda linha, calcula: Linha 2 + (-2) × Linha 1.
O que dá?
— O resultado seria [0, 0 | 1].
Isso. Olha essa linha: [0, 0 | 1].
Ela diz: 0x + 0y = 1.
Isso é possível?
— Isso não seria possível.
Exato. Contradição. O sistema não tem solução.
Isso aparece na eliminação quando surge uma linha [0, 0, ..., 0 | c] com c ≠ 0.
Agora a outra matriz:
| 1 2 | 2 |
| 2 4 | 4 |
Linha 2 + (-2) × Linha 1. O que dá?
— O resultado seria [0, 0 | 0].
Isso. A linha [0, 0 | 0] diz: 0 = 0.
Verdade, mas não dá informação. A equação sumiu — era redundante.
Sobrou só uma equação: x + 2y = 2.
Uma equação, duas incógnitas. O que isso significa?
— Acho que não sei.
Pensa assim: você pode escolher y livremente.
Se y = 0, então x = 2. Se y = 1, então x = 0. Se y = 2, então x = -2.
Infinitas soluções. Uma variável livre.
A variável livre corresponde ao espaço nulo. Lembra que o espaço nulo tinha dimensão 1? Aqui aparece como uma variável que você escolhe.
Resumo da eliminação gaussiana.
| Resultado | Significado | |-----------|-------------| | Todos os pivôs, sem contradição | Solução única | | Linha [0, 0, ... | c] com c ≠ 0 | Sem solução | | Linha [0, 0, ... | 0] | Variável livre → infinitas soluções |
O número de pivôs é o rank. O número de variáveis livres é a dimensão do espaço nulo.
Diálogo 9. Matrizes inversas — quando e por quê.
— Você viu que resolver A × x = b é achar x dado A e b.
Se existisse uma matriz A⁻¹ tal que A⁻¹ × A = I (a matriz identidade), então:
A × x = b A⁻¹ × A × x = A⁻¹ × b x = A⁻¹ × b
A solução viria direto. Mas nem toda matriz tem inversa.
Qual matriz é a identidade I para 2×2?
— Seria a matriz [[1, 0], [0, 1]].
Isso. A identidade não muda nada: I × v = v para qualquer v.
Agora a pergunta: quando uma matriz tem inversa?
Pensa na matriz:
A = | 1 2 |
| 2 4 |
Essa matriz tem rank 1. O espaço nulo tem dimensão 1 — ela mata vetores.
Se A mata algo, dá pra desfazer? Se A × v = [0, 0] para v ≠ [0, 0], existe A⁻¹ que recupera v a partir de [0, 0]?
— Assim não entendi.
Vou de outro jeito.
A matriz A = [[1,2],[2,4]] transforma:
- [0, 0] → [0, 0]
- [-2, 1] → [0, 0]
- [-4, 2] → [0, 0]
Três vetores diferentes vão pro mesmo lugar.
Se eu te der [0, 0] e perguntar "de onde veio?", você consegue responder?
— Pode ter sido gerado com algum dos vetores.
Exato. Não dá pra saber. A informação se perdeu.
Por isso A não tem inversa. Ela não é injetora — vetores diferentes vão pro mesmo lugar.
Agora outra matriz:
B = | 1 2 |
| 3 4 |
Essa tem rank 2. O espaço nulo é só {[0, 0]}.
Só o vetor zero vai pro zero. Cada vetor de entrada produz uma saída diferente.
Essa matriz tem inversa. Dá pra desfazer porque nada se perde.
Regra: uma matriz tem inversa se e somente se o rank é máximo (igual ao número de linhas e colunas).
Para uma matriz n×n, isso significa rank = n, espaço nulo = {0}.
Vamos achar a inversa de B. Se B × B⁻¹ = I, então:
| 1 2 | | a b | | 1 0 |
| 3 4 | × | c d | = | 0 1 |
Cada elemento do resultado:
- Posição (1,1): linha 1 de B · coluna 1 de B⁻¹ = 1a + 2c
- Posição (1,2): linha 1 de B · coluna 2 de B⁻¹ = 1b + 2d
- Posição (2,1): linha 2 de B · coluna 1 de B⁻¹ = 3a + 4c
- Posição (2,2): linha 2 de B · coluna 2 de B⁻¹ = 3b + 4d
Então:
| 1a + 2c 1b + 2d | | 1 0 |
| 3a + 4c 3b + 4d | = | 0 1 |
Isso dá quatro equações:
1a + 2c = 1 3a + 4c = 0 1b + 2d = 0 3b + 4d = 1
As duas primeiras formam um sistema para achar a e c. As duas últimas formam outro sistema para achar b e d.
— Eu não sei como resolver. Aqueles exemplos foram resolvidos porque eram mais simples, mas qual seria o jeito correto? A eliminação gaussiana?
Isso. Eliminação gaussiana. Vamos aplicar.
Sistema:
a + 2c = 1 3a + 4c = 0
Matriz aumentada:
| 1 2 | 1 |
| 3 4 | 0 |
Linha 2 + (-3) × Linha 1:
[3, 4 | 0] + (-3) × [1, 2 | 1] = ?
— O resultado seria [0, -2 | -3].
Isso. Agora a matriz fica:
| 1 2 | 1 |
| 0 -2 | -3 |
Segunda linha: -2c = -3. Quanto é c?
— O c não tem como ser encontrado.
Tem sim. É só dividir.
-2c = -3
c = -3 / -2 = 3/2
Não precisa ser inteiro. c = 3/2.
Agora substitui na primeira linha: a + 2c = 1.
a + 2 × (3/2) = 1 a + 3 = 1 a = ?
— Tá. Iria já te perguntar isso mesmo depois. O a seria -2.
Isso. Então a primeira coluna de B⁻¹ é [-2, 3/2].
Agora o segundo sistema para b e d:
b + 2d = 0 3b + 4d = 1
Matriz aumentada:
| 1 2 | 0 |
| 3 4 | 1 |
Linha 2 + (-3) × Linha 1:
[3, 4 | 1] + (-3) × [1, 2 | 0] = [3, 4 | 1] + [-3, -6 | 0] = [0, -2 | 1]
Então a matriz fica:
| 1 2 | 0 |
| 0 -2 | 1 |
Segunda linha: -2d = 1. Quanto é d?
— O d seria -1/2.
Isso. Agora substitui na primeira linha: b + 2d = 0.
b + 2 × (-1/2) = 0 b - 1 = 0 b = ?
— O b seria 1.
Isso. Então a segunda coluna de B⁻¹ é [1, -1/2].
A inversa completa:
B⁻¹ = | -2 1 |
| 3/2 -1/2 |
Vamos verificar. B × B⁻¹ deve dar I.
Calcula a posição (1,1): linha 1 de B · coluna 1 de B⁻¹.
[1, 2] · [-2, 3/2] = 1×(-2) + 2×(3/2) = ?
— Sim, deu 1.
Isso. Pode verificar as outras posições — todas batem.
Resumo das matrizes inversas.
- A⁻¹ existe se e somente se A tem rank máximo (espaço nulo = {0}).
- Se A mata vetores, não tem inversa — informação se perde.
- Para achar A⁻¹, resolve n sistemas com eliminação gaussiana.
- A × A⁻¹ = A⁻¹ × A = I.
- Se A⁻¹ existe, A × x = b tem solução única: x = A⁻¹ × b.
Conclusão.
Bom, esses foram os diálogos da segunda parte de Álgebra Linear para a Elite em IA.