A geometria de um perceptron
A compreensão com a geometria ajuda muito na construção de um aprendizado forte sobre redes neurais.
Quando estudamos redes neurais, geralmente pensamos nos dados, que podem ser pensados como pontos que queremos separar em categorias.
Tem outro modo de ver o mesmo problema: pelo espaço de pesos.
Neste post, vou explicar três slides clássicos de Geoffrey Hinton sobre esse tema. Mas antes, precisamos aprender ou revisar pré-requisitos básicos.
Parte 0. Os pré-requisitos que vamos precisar.
Um número como posição.
Imagine uma régua. Cada número marca uma posição. O zero é um ponto de referência, a origem. O número 3 está a 3 centímetros da origem. O -2 está a 2 centímetros para o outro lado.
Duas dimensões, dois números.
Agora imagine um mapa. Para marcar onde fica uma cidade, um número só não basta. Você precisa de dois: "5km para leste, 3km para sul".
Isso é um par de coordenadas, que escrevemos como (5, 3).
Os dois eixos (leste-oeste e norte-sul) são como duas réguas perpendiculares. Juntas, elas cobrem o mapa todo. Chamamos isso de espaço bidimensional.
O que é um ponto.
Um ponto é simplesmente uma posição. No mapa, (5, 3) é um ponto, o lugar onde as duas coordenadas se encontram.
O que é um vetor.
Um vetor é uma seta que vai da origem até um ponto. O ponto (5, 3) e o vetor (5, 3) têm os mesmos números. A diferença é conceitual.
- Ponto = "onde estou".
- Vetor = "como chegar lá partindo da origem".
Para nossos propósitos, são quase a mesma coisa.
Mais dimensões.
Com 3 números, como por exemplo (2, 5, 3), descrevemos posições no espaço 3D (leste, sul e altura).
Com 80 números? Nós não conseguimos visualizar, mas a matemática funciona igual. Cada número é uma "direção" independente.
O produto escalar, o coração de tudo.
Dados dois vetores, digamos a = (2, 3) e b = (4, 1), o produto escalar é:
a · b = 2×4 + 3×1 = 8 + 3 = 11.
Multiplicamos os elementos de cada vetor que estão na mesma posição do índice, depois somamos.
O que esse número significa?
Ele mede o quanto dois vetores apontam na mesma direção.
Para entender melhor, existe uma fórmula alternativa:
a · b = |a| × |b| × cos(θ).
Onde |a| e |b| são os comprimentos dos vetores (sempre positivos), e θ é o ângulo entre eles.
O cosseno é uma função que varia entre +1 e -1. Quando dois vetores apontam na mesma direção (0°), o cosseno é +1 e o produto escalar é máximo positivo. Quando são perpendiculares (90°), o cosseno é 0 e o produto escalar também. Quando apontam em direções opostas (180°), o cosseno é -1 e o produto escalar é máximo negativo.
A intuição: o cosseno mede "quanto um vetor aponta na direção do outro".
Ângulo pequeno → apontam juntos → produto positivo.
Ângulo de 90° → perpendiculares → produto zero.
Ângulo grande → apontam em direções opostas → produto negativo.
Guarde isso. É a chave para tudo que vem a seguir.
Parte 1. O Espaço de Pesos.
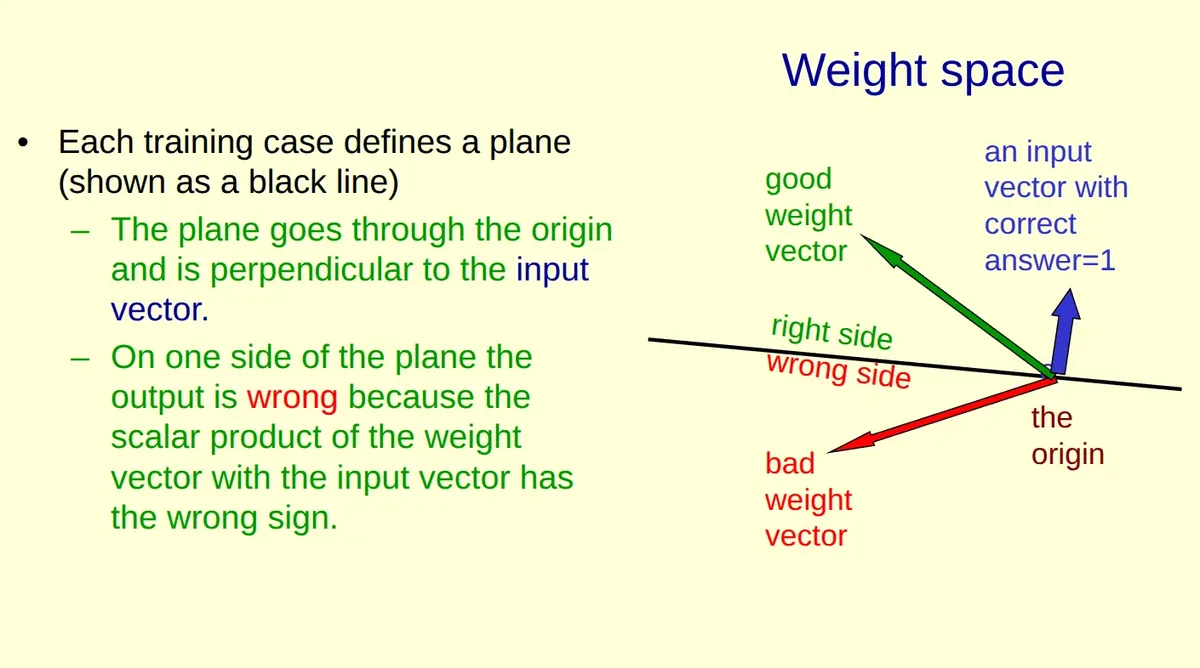
Cada ponto como uma configuração de pesos, ou um modelo.
O perceptron é um modelo simples: ele recebe um vetor de entrada x, multiplica pelos pesos w, e calcula w · x. Se o resultado for positivo, diz "classe 1". Se for negativo, diz "classe 0".
Normalmente pensamos no espaço de entrada, onde cada ponto é um exemplo de dado. Mas o slide propõe outra visão: o espaço de pesos (weight space).
No espaço de pesos, cada ponto representa uma configuração possível de pesos do modelo. É como perguntar: "de todos os pesos possíveis que eu poderia escolher, quais funcionam?"
O que cada elemento do slide significa.
O vetor azul (input vector): É um exemplo de treinamento específico, um vetor de entrada com suas coordenadas. Ele vem com um rótulo "correct answer = 1".
O vetor verde e o vetor vermelho: São pontos no espaço de pesos. Cada um representa uma configuração de pesos distinta. O verde é uma boa escolha; o vermelho é ruim.
A linha (o "plano"): Aqui está a ideia central. Dado o input x, a linha representa todos os vetores de peso w tais que w · x = 0.
Lembra que w · x = 0 acontece quando o ângulo entre eles é exatamente 90°? Então a linha cinza é a fronteira dos 90 graus — o conjunto de pesos perpendiculares ao input.
Por que isso importa?
Se o rótulo correto é 1, precisamos que w · x > 0 (resultado positivo).
Pela relação com o cosseno, w · x > 0 acontece quando o ângulo é menor que 90°, e w · x < 0 acontece quando o ângulo é maior que 90°.
A linha cinza divide o espaço de pesos em duas regiões. O lado certo contém pesos que dão a resposta certa, com ângulo menor que 90° e produto positivo. O lado errado contém pesos que dão a resposta errada, com ângulo maior que 90° e produto negativo.
O vetor verde está do lado certo. O vermelho está do lado errado.
Resumindo.
Um training case (exemplo de treinamento) é o par: vetor de entrada + seu rótulo. Cada training case define um hiperplano no espaço de pesos. Esse hiperplano divide os pesos em "bons" e "ruins" para aquele exemplo específico.
Parte 2. Interpretação para a classe 0.
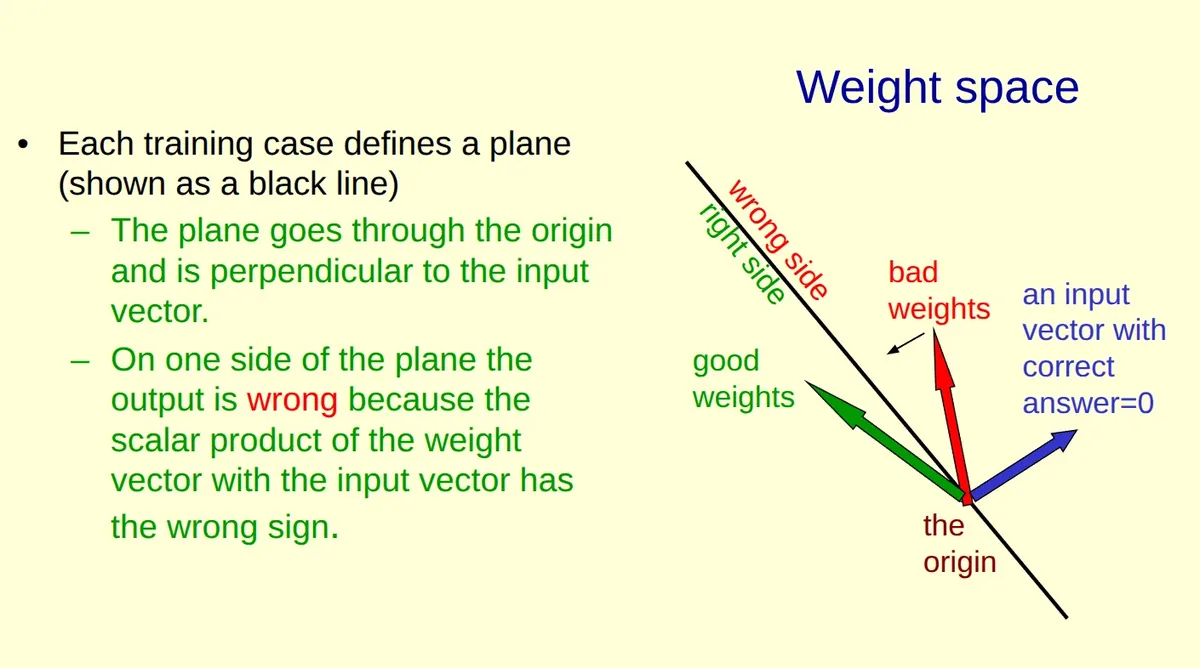
Quando a resposta certa é não.
Agora o input vector tem rótulo 0 (ou seja, queremos saída negativa).
Agora queremos que o modelo diga "classe 0".
Precisamos de w · x ≤ 0.
Ou seja, ângulo ≥ 90°.
Os bons pesos ficam do lado distante do input.
Compare com o slide anterior.
Quando o rótulo é 1, queremos produto positivo — o peso deve apontar junto com o input.
Quando o rótulo é 0, queremos produto negativo — o peso deve apontar para longe.
Repare como no segundo slide o vetor verde (good weights) aponta para o lado oposto do azul, enquanto no primeiro eles apontavam mais ou menos na mesma direção.
O hiperplano continua sendo a fronteira dos 90°. O que muda é qual lado é considerado "certo" — e isso depende do rótulo.
Parte 3. O Cone de Soluções Viáveis.
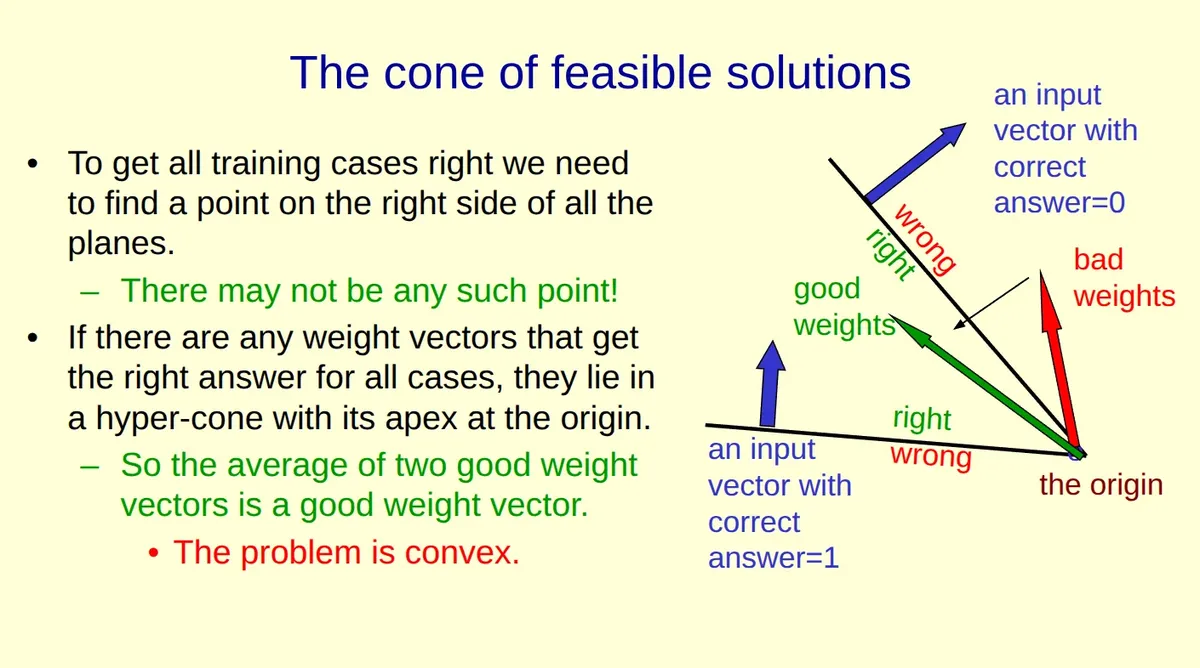
Múltiplos exemplos para múltiplos cortes.
Agora temos dois training cases (dois inputs azuis), cada um com seu próprio hiperplano:
Input de cima: label = 0 → bons pesos devem fazer ângulo > 90° com ele.
Input de baixo: label = 1 → bons pesos devem fazer ângulo < 90° com ele.
Para acertar ambos os exemplos simultaneamente, o peso precisa estar do lado certo de ambos os hiperplanos.
A geometria da interseção.
Considere duas linhas cruzando na origem. Elas dividem o plano em 4 regiões. Apenas uma dessas regiões satisfaz as duas condições ao mesmo tempo.
Essa região tem formato de cone com a ponta na origem. O vetor verde está dentro dessa região. O vermelho está fora.
E se houver mais exemplos?
Cada novo training case adiciona mais um corte. A região viável fica cada vez mais estreita — um cone mais "apertado".
Se os exemplos forem contraditórios (o problema não é linearmente separável), a região pode desaparecer completamente. Por isso o slide avisa: "There may not be any such point!"
A média de dois bons pesos dá um resultado bom.
Se w₁ está dentro do cone e w₂ está dentro do cone, o que acontece com a média deles?
A média de dois vetores é simplesmente o ponto no meio do caminho:
w_média = (w₁ + w₂) / 2
Por que a média também é boa?
Pense no cone. Se dois pontos estão dentro dele, a linha reta entre eles também está. O ponto médio, que está nessa linha, necessariamente está dentro do cone.
O problema é convexo.
Uma região é convexa se, para quaisquer dois pontos dentro dela, toda a linha reta entre eles também está dentro.
Um círculo é convexo. Um quadrado é convexo. Uma estrela não é convexa, a linha entre duas pontas passa por fora.
Por que isso importa?
Problemas de otimização convexos são "bem comportados". Eles não têm mínimos locais falsos — armadilhas onde o algoritmo acha que encontrou a solução, mas na verdade existe algo melhor em outro lugar.
Para o perceptron, se a região viável existe (o problema é linearmente separável), qualquer algoritmo razoável de busca vai encontrar uma solução. Essa é a garantia teórica por trás da convergência do perceptron.
Conclusão.
A mudança do espaço de entrada para o espaço de pesos transforma o problema de "separar dados" em "encontrar um ponto numa região".
Cada exemplo de treinamento vira um corte no espaço. O conjunto de pesos que funciona é a interseção de todos os "lados certos" — um cone convexo.
Essa perspectiva geométrica não é apenas bonita. Ela explica por que o perceptron converge quando a solução existe, por que ele falha quando não existe interseção, e por que o problema é tratável computacionalmente graças à convexidade.
Geoffrey Hinton, nestes três slides simples, captura décadas de intuição sobre aprendizado linear.